
Author: Ann Harding (SWITCH)
You’ve seen the lightning talk at TNC2016 (you have, of *course* you have), and maybe you were even in the audience at REFEDs – now it’s time to slow down and let the ideas settle as you read a coffee-break blog.
Back in 2002, a much referenced paper, The Rationale of Optical Networking, by Cees de Laat, Erik Radius, Steven Wallace, highlighted the gap in requirements between the many simple uses of networking, and the few highly intensive scientific applications. While over time, the bandwidth requirements of the commodity end have now exceeded what people used to consider ‘advanced’ speeds, the model still holds as a way of understanding the role of a research network.
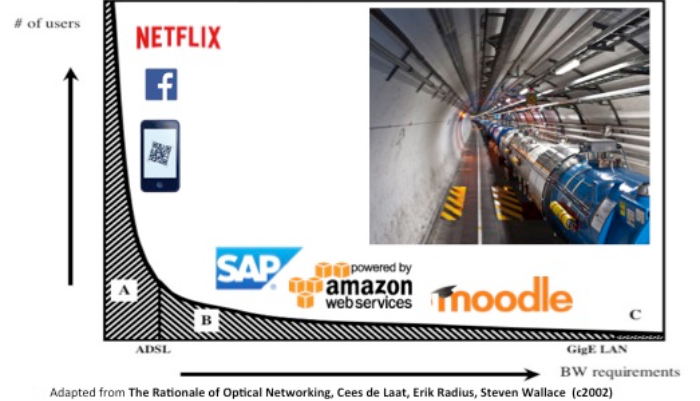
This work has inspired the creation of the ‘Science DMZ’ concept to balance the requirements of campuses to serve both the large numbers of simple use cases and the small number of high intensity cases without having to adjust an entire infrastructure.
Having spent three years working intensively with the requirements of research users in federated identity management, seeing the amazing progress made to date for entity categories, assurance, incident response and interoperability but also the difficulties in going to the next level and the frustration for both federation operators and research organisations in making these steps, I wondered if the Science DMZ approach might also map well to the identity world and help us break this challenge down into manageable chunks.
The first thing to do was therefore to understand our own ‘curve’ of classes of users. I therefore took a copy of the eduGAIN metadata in April 2016 and set about manually identifying and classifying the types of services to see how large the potential need is vs. the generic education focussed infrastructure. The X axis for identity management is complexity, rather than bandwidth. Specifically this includes aspects such as the lack of a formal contractual arrangement with a campus institution or on a single country basis, the requirement to have reliable attribute information, to have greater than normal assurance about the identity of a user, to be able to combine attributes about a user from multiple sources and other similar aspects which are not required for a basic identity federation service.
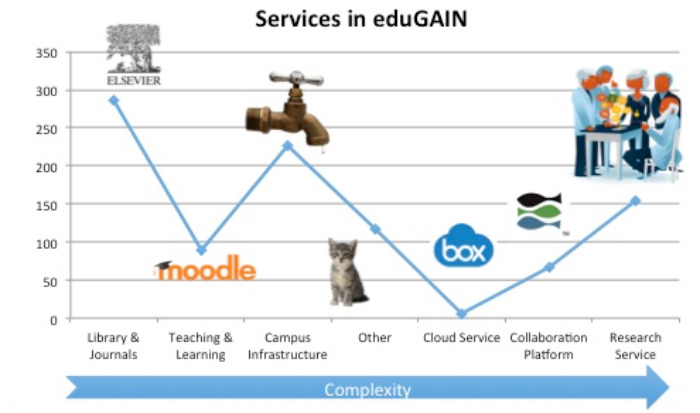
- Class A) are the traditional library/journal/learning applications
- Class B) consists of the campus ‘corporate’ infrastructure
- Class C) are the really complex trust applications for collaboration and e-Research. This includes ‘Open Access’ style library services
One observation is that the edges between the segments are not necessarily clean in terms of target user. The same user may read an article in a journal, prepare the material for the online course they are delivering, book a parking space in the campus parking management system, upload a test application to an AWS instance and go compare the results with an open data set before discussing on a wiki how to organise the paper they will write with their collaboration partners. So the challenge is to make it simple and easy for that user to use a single set of credentials for all these services, while making it possible for the services to make complex authorisation decisions without unfairly distributing work to all parties. This is equivalent to the network DMZ where the researcher is not prevented from using ‘normal’ services from their IP range in a DMZ, only facilitated in the advanced needs.
The second observation is that our service picture is actually quite diverse. In the interfederation context, while the traditional services are still the majority, they are not overwhelmingly so. This is also likely to be a changing picture as NRENs increase their engagement with research. CORDIS is a database of EU-funded research which gives some emphasis into potential growth. Statistics from CORDIS indicate NRENs’ members are the leading successful applicants, with 5799 universities and 4164 research organisations receiving funding in Horizon2020. By the nature of the Horizon2020 programme, it is a reasonable assumption that each of these organisations is working with at least one other, probably in another country. If only 10% of those end up hosting resources such as datasets, applications or even collaboration platforms, we almost double the number of services in eduGAIN, and all complex ones. We need to support these users, but not burden our campuses or compromise their trust in our infrastructure. This is where segmenting a Science DMZ may be a promising approach.
So, what does this Science DMZ look like? For a network DMZ there are some guidelines on design patterns:
- Design pattern 1: Protect your elephant flows
- Design pattern 2: Unclog your data taps
- Design pattern 3: Build a well tuned end-to-end infrastructure
For trust and identity, we want to enable the smooth flow of trust, not of packets, but we can lightly tweak the above principles:
- Design pattern 1: Enable your collaboration flows
- Design pattern 2: Unclog your policy taps
- Design pattern 3: Build a well trusted end-to-end infrastructure
This is all very nice, but what could it look like in practice?
- Design pattern 1: Enable your collaboration flows
- Export IdPs to eduGAIN
- Find and export eResearch SPs to eduGAIN
- Design pattern 2: Unclog your policy taps
- For hub and spoke – do you need the same policies for your C users as for your a and B? Can you be more flexible?
- For full mesh – do you need to leave everything to the edges? Can you use your resource registry/central tools to apply policy for e-research more scalably?
- Pragmatic assurance
- Longer term – adopt user-centric identity, to remove the burden of personal data management from the campus, while preserving affiliation information.
- Design pattern 3: Build a well trusted end-to-end infrastructure
- Use Research and Scholarship and GÉANT Code of Conduct Entity Categories to make trust scale beyond your federation
- Adopt SIRTFI incident response framework to build trust
- Adopt interoperable group and attribute management services e.g. VO Platform as part of an overall architecture.






Add Comment